STL6--模板进阶:非类型参数、模板特化与分离编译机制解析
📌 创作初心:在构建个人知识体系的同时,希望帮助更多正在学习 C++ 模板机制的同学
📚 系列专栏:柯一梦的STL进阶之路
💡 座右铭:功不唐捐,玉汝于成
🎯 本文目标:
- 理解非类型模板参数的设计意义与使用方式
- 掌握函数模板与类模板的特化机制(全特化 / 偏特化)
- 理解 const、引用与指针在模板推导中的作用
- 搞清模板分离编译的本质原因与解决方案
- 建立对 STL “header-only 设计”的底层认知
🧠 阅读建议:本文涉及模板底层机制与编译原理,建议先掌握函数模板基础、类模板基础以及 C++ 编译流程(预处理 / 编译 / 链接)
模版支持:泛型编程
非类型模版参数
模版参数分为类型参数和非类型参数
类型形参:出现在模版的参数列表中,跟在class或者typename的关键字之后的参数类型名称
非类型形参:用一个常量作为类(函数)模版的一个参数,在类(函数)模版中,可以将该参数当作常量来使用
我们用静态栈来举一个例子,说明一下我们为什么要学习非类型模版参数
1 |
|
==这段代码就是我们学习c语言的时候写的静态数组,但是它的弊端是我们只能创建大小是100的数组==
1 | namespace rxj |
- 对于静态栈,我们使用宏来控制一个对象的数组大小,使用类型模版控制数组成员类型。不同对象可以存入不同类型数据,==但是只能分配相同的大小空间
- 类型参数的话,函数模版可以传对象,类模版只能传类型或者常量(常量:非类型模版参数)
- 模版参数可以给缺省值,全缺省值我们要用Stack<> s1去实例化对象
- 非类型模版参数的应用:一个容器:静态数组arry。普通数组没法查出来你有没有非法访问,但是静态数组可以。
==注意==1.非类型模版参数只支持整型家族
2.浮点数、类对象以及字符串是不被允许作为非类型模版参数的
模版的特化
==特化的概念==:通常情况下,使用模版可以实现一些与==类型==无关的代码,但是对于一些特殊类型的,可能会得到一些错误的结果。比如:
1 | template<class T> |
从还是那个面那个例子可以看出,函数模版可以解决大多数例子,但是针对特殊场景就得到错误的结果。此时,我们就需要对模版进行特化。即:在原模版类的基础上,针对特殊类型实现特殊化的实现方式。模版特化分为函数模版特化和类模版特化
函数模版特化
函数模版特化的步骤:
- 必须要有一个基础的函数模版
- 关键字template后面接一对空的尖括号<>
- 函数名后面跟一对尖括号 ,尖括号中指定需要特化的类型
- 函数形参列表:必须要和函数模版基础参数类型完全相同
- ==注意==我们在写模版函数的时候:内置类型值传参和引用传参代价差别不大;而自定义类型就很大。既然我们不知道是什么类型,所以我们要引用传参,既然是引用传参,就有改变的风险,所以我们要加const
我们现在对上面的那个例子进行一下优化:
1 | template<class T> |
但是这段代码有一个问题,针对我们的第五条规则,我们应该对参数进行引用和const修饰,但同样的我们的模版特化也应该保持一致。但问题是如何保持一致呢?首先我们要知道const T& left中的const修饰的是谁,const修饰的是left本身
对于const与指针之间的关系:这三种写法都是正确的
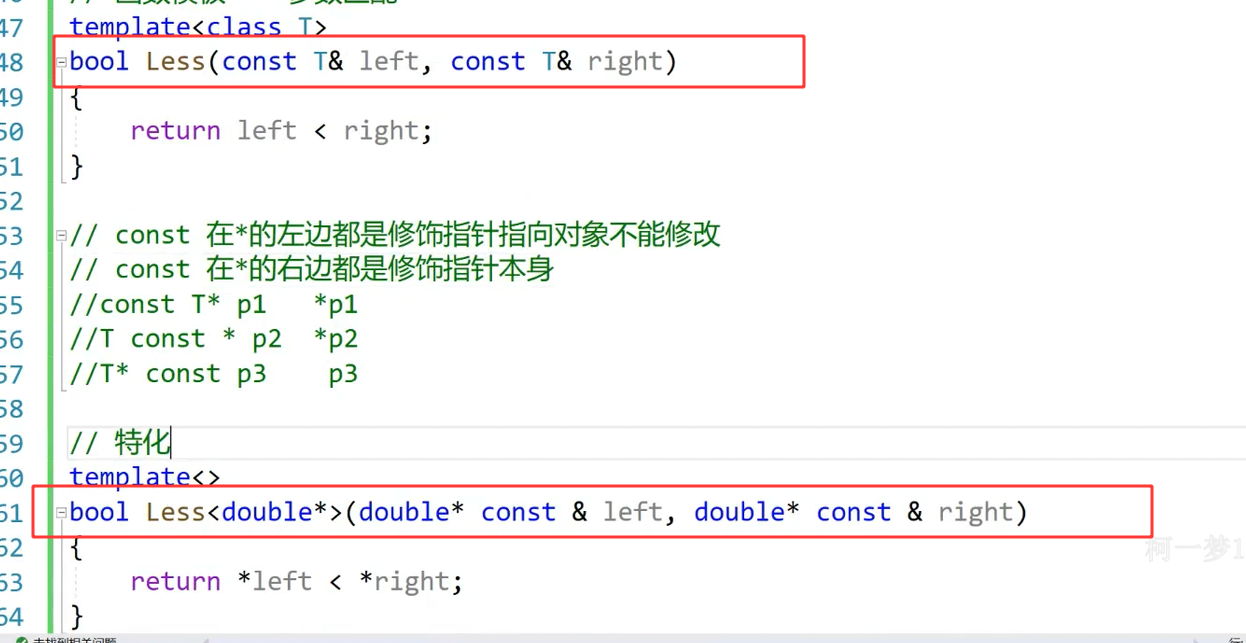
听我讲解为什么这个可以这样使用:主模版的const修饰的是left引用的T类型的对象不能修改,我们传入的是double*,翻译过来也就是我们引用的那个double* 对象不能修改,而不是说指针指向的对象的值不能修改,所以const就应该在* 和变量之间,修饰指针本身,&在类型后面就行
所以,正确写法应该是下面这段
1 | template<class T> |
但其实我们可以不使用函数模版特化,可以使用函数重载。因为函数模版和同名函数是可以同时存在的。可以构成重载
- 对于类模版来说:有全特化和偏特化。成员变量可以不写 (类里面是随便写的,相当于写了一个全新的类,和原本的类没有关系)
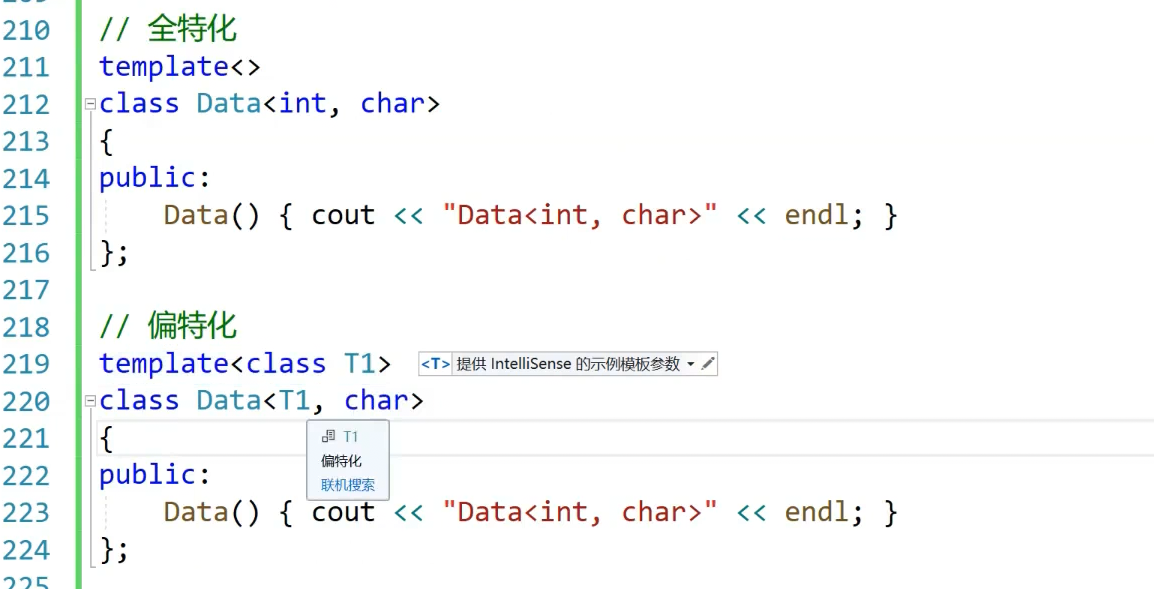
类模版的特化
全特化
全特化就是将模版参数列表中的所有参数都确定化
1 | template<class T1,class T2> |
==注意==:
1.首先要有一个模版类
2.在进行特化的时候,把需要特化的参数从模版参数列表中除去,然后将其写在类名后面,并且将类中之前涉及到的模版参数都进行依次的替换
3.==全特化本质上已经不是“模板”了,全特化后的类不再依赖模板参数,而是一个普通类,==
偏特化
偏特化:偏特化是对模板参数进行“部分具体化”或“形式限制”,用于匹配某一类类型,而不是某个具体类型。比如下面这个类:
1 | template<class T1,class T2> |
偏特化有两种形式:
- 部分特化
1 | template<class T2> |
==注意==:
1对于不特化的参数还要写在关键字template<>里面,并且类后面的<>既要写偏特化的类型,也要写未偏特化的参数类型
2.别忘了修改类中已经被实例化的模版参数
- 对模板参数进行“形式匹配限制”(如指针、引用等)
1 | template<class T1,class T2> |
==注意==:
1.若是对参数进行进一步的限制,比如加上一个指针或者引用时,template后面的参数不能省略
2.当模板参数为 T* 时,模板匹配会进行“模式拆解”,将实参类型 int* 拆解为:T = int 。因此 T 接收的是去掉指针后的类型
==总结==:当存在多个匹配的模板时,编译器会选择“最特化”的版本:
全特化 > 偏特化 > 主模板
模版分离编译
==要想懂的模版分离编译,就不得不先了解c++的编译流程==
- 预处理(文本替换)
- 编译(变成汇编)
- 汇编(变成机器码)
- 链接(拼成可执行文件)
预处理
预处理阶段只进行纯文本处理。主要包含:1、头文件展开 2、宏替换 3、条件编译 4、去掉注释。
编译
编译阶段会进行语法分析,并且生成汇编语言。
汇编
把汇编变成机器码。.o文件里有符号表(将函数简化成一个符号)和已经编译好的函数
链接
把所有.o文件拼起来。其中最重要的就是符号解析。
==总结==:在 预处理阶段,头文件只是被文本展开;到了 编译阶段,编译器根据声明检查语法,并生成目标文件(.o),其中函数调用不会变成具体地址,而是记录为“未解析的符号引用”,同时函数定义会被编译成机器码并导出为“已定义符号”;最后在 链接阶段,链接器会收集所有 .o 文件的符号表,把“未定义符号”和“已定义符号”进行匹配,统一分配实际内存地址,并将调用处的符号引用回填为真实地址,从而生成最终可执行文件。
为什么模版的分离编译会报错呢?
模板在使用时会发生隐式实例化,编译器必须在使用点看到完整定义才能生成具体代码。如果模板定义放在
.cpp文件中,其他编译单元无法看到定义,就无法实例化对应版本的函数或类,最终导致链接阶段找不到符号,从而报错。
解决方法:
我们可以把声明和定义写在一个文件里。但是值得一提的是如果函数的定义在类里,那么就是内联函数。所以我们可以把长一点的函数进行声明和定义分离:即声明在类里,定义在类外,但都是在一个文件中